

引言:当AI遇见时尚
"推荐3套适合约会的优雅穿搭"——这样一句简单的自然语言请求,背后需要怎样的技术栈来实现?
最近我完成了一个有趣的项目:Stylist MCP Server,一个AI驱动的时尚推荐服务。它能理解用户的穿搭需求(支持中英文),从53,789件服装数据库中智能检索,并给出专业的搭配建议。更重要的是,它遵循Anthropic的Model Context Protocol (MCP)标准,可以无缝集成到Claude Desktop、Cursor等AI工具中。
今天,我想分享整个开发过程中的设计思路、技术选型和踩坑经验。
项目架构总览
在深入细节之前,先看看整体架构:
┌─────────────────┐ ┌─────────────────┐
│ Claude Desktop │ │ │
│ / Cursor │──┬── stdio ──────────────────│ │
└─────────────────┘ │ │ │
├── SSE (legacy) ───────────│ MCP Server │──▶ ChromaDB
┌─────────────────┐ │ │ (Starlette) │ (53,789 items)
│ VS Code │──┴── Streamable HTTP ⭐ ─────│ │
│ + Skill │ (推荐) │ │
└─────────────────┘ └────────┬────────┘
│
┌────────▼─────────┐
│ LLM Client │
│ ├─ Anthropic │
│ ├─ Azure OpenAI │
│ └─ OpenAI │
└──────────────────┘
核心组件包括:
- MCP Server: 基于Starlette的异步HTTP服务,支持三种传输模式(stdio/SSE/Streamable HTTP)
- ChromaDB: 向量数据库,存储服装的语义嵌入和元数据
- LLM Client: 统一的大模型接口层,支持多provider切换
- Skill Layer: 配套的展示层,将MCP返回结果转化为精美的可视化报告
- Nginx + Let's Encrypt: 生产环境的HTTPS反向代理
第一步:构建服装向量索引
数据源:DressCode数据集
我使用的是DressCode数据集,包含约54,000张高质量服装图片,分为三个类别:
upper_body: 上装(T恤、衬衫、外套等)lower_body: 下装(裤子、裙子、短裤等)dresses: 连衣裙
每件服装都有详细的属性标注,包括颜色、风格、适用场合、季节等。
ChromaDB索引构建
ChromaDB的优势在于开箱即用的向量搜索能力,同时支持元数据过滤。我的索引策略是:
# 将服装属性转换为自然语言描述
def build_description(attrs: dict) -> str:
parts = []
if attrs.get("colors"):
parts.append(f"Colors: {', '.join(attrs['colors'])}")
if attrs.get("styles"):
parts.append(f"Styles: {', '.join(attrs['styles'])}")
if attrs.get("occasions"):
parts.append(f"Occasions: {', '.join(attrs['occasions'])}")
# ... 更多属性
return " | ".join(parts)
# 添加到ChromaDB
collection.add(
ids=[garment_id],
documents=[description], # 用于语义搜索
metadatas=[{
"category": "upper_body",
"garment_type": "t-shirt",
"colors": json.dumps(["white", "blue"]),
# ... 结构化元数据用于过滤
}]
)
关键设计决策:
- 描述文本用于语义搜索:将属性拼接成自然语言,让嵌入模型理解语义
- 元数据用于精确过滤:category、garment_type等字段支持精确匹配
- 混合检索策略:先用元数据缩小范围,再用向量相似度排序
构建完成后,53,789件服装被索引到ChromaDB,支持毫秒级检索。
第二步:LLM意图解析
用户的自然语言请求需要被解析为结构化的搜索参数。这是整个系统的"大脑"。
Prompt工程:跨模型兼容性
最初我的prompt是这样的:
Extract the following parameters:
1. LANGUAGE & MODE DETECTION:
- language: "zh" | "en"
- recommendation_mode: "single_item" | "full_outfit"
...
2. GARMENT FILTERS:
- garment_type: ...
...
这个prompt在Claude Haiku上工作完美,但切换到GPT-4o-mini时出问题了——GPT返回了嵌套的JSON结构,完全按照prompt中的分类标题组织:
{
"LANGUAGE & MODE DETECTION": {
"language": "en",
"recommendation_mode": "single_item"
},
"GARMENT FILTERS": { ... }
}
而我的代码期望的是扁平结构:intent.get("recommendation_mode")直接返回None!
教训:不同LLM对prompt的理解方式不同。GPT更"忠实"地遵循格式,Claude更"聪明"地推断意图。
解决方案:重写prompt,明确要求扁平JSON:
Extract these parameters and return a FLAT JSON object (no nested objects):
- language: "zh" | "en"
- recommendation_mode: "single_item" | "full_outfit"
- garment_type: one of ["dress", "t-shirt", ...] or null
...
IMPORTANT: Return ONLY a flat JSON object with all fields at the top level.
Do NOT use nested structures or category headers.
修改后,两个模型都能正确返回扁平JSON,测试全部通过(14/14)。
第三步:多模型LLM支持
为了同时支持开发环境(本地Agent Maestro代理Claude)和生产环境(Azure OpenAI GPT-4o-mini),我设计了一个统一的LLM抽象层:
# src/llm_client.py
from abc import ABC, abstractmethod
class LLMClient(ABC):
@abstractmethod
def chat(self, messages: list, max_tokens: int, timeout: int) -> str:
pass
class AnthropicClient(LLMClient):
"""支持Agent Maestro代理或直接Anthropic API"""
def chat(self, messages, max_tokens=1024, timeout=60):
response = httpx.post(
self.endpoint,
json={"model": self.model, "messages": messages, "max_tokens": max_tokens},
timeout=timeout
)
return response.json()["content"][0]["text"]
class AzureOpenAIClient(LLMClient):
"""Azure OpenAI服务"""
def chat(self, messages, max_tokens=1024, timeout=60):
# 转换消息格式(Anthropic -> OpenAI)
openai_messages = self._convert_messages(messages)
response = self.client.chat.completions.create(
model=self.deployment,
messages=openai_messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
def get_llm_client() -> LLMClient:
"""工厂函数,根据环境变量选择provider"""
provider = os.getenv("LLM_PROVIDER", "anthropic")
if provider == "azure_openai":
return AzureOpenAIClient()
elif provider == "openai":
return OpenAIClient()
else:
return AnthropicClient()
配置切换只需修改环境变量:
# 开发模式(Agent Maestro代理Claude)
LLM_PROVIDER=anthropic
LLM_API_ENDPOINT=http://localhost:23333/api/anthropic/v1/messages
# 生产模式(Azure OpenAI)
LLM_PROVIDER=azure_openai
AZURE_OPENAI_ENDPOINT=https://xxx.openai.azure.com
AZURE_OPENAI_DEPLOYMENT=gpt-4o-mini
性能对比:
| 模型 | 完整穿搭推荐耗时 | 测试通过率 |
|---|---|---|
| Claude Haiku | ~22秒 | 14/14 |
| GPT-4o-mini | ~9秒 | 14/14 |
GPT-4o-mini在响应速度上明显更快,非常适合生产环境。
第四步:多传输模式与远程访问
MCP协议支持三种传输模式:
- stdio: 本地进程通信,适合Claude Desktop直接集成
- SSE (Server-Sent Events): HTTP长连接,传统远程访问方式
- Streamable HTTP ⭐: 最新推荐的远程访问方式,配置更简洁
对于跨机器访问(比如从我的MacBook连接到Azure VM上的服务),远程传输模式是必须的。
Streamable HTTP:更简洁的远程访问(推荐)
Streamable HTTP 是 MCP 协议的最新传输方式,相比 SSE 有明显优势:
| 特性 | SSE | Streamable HTTP |
|---|---|---|
| 配置复杂度 | 需要 mcp-remote 中转 | 直接 URL 连接 |
| 客户端支持 | 需要 npx 命令 | 原生支持 |
| 配置行数 | 6-8 行 | 3-4 行 |
Streamable HTTP 客户端配置(以 VS Code/Cursor 为例):
{
"mcpServers": {
"stylist-recommender": {
"url": "https://stylist.polly.wang/mcp",
"headers": {
"X-API-Key": "YOUR_API_KEY"
}
}
}
}
就这么简单!不需要 npx,不需要 mcp-remote,直接填 URL 和认证信息即可。
对比传统 SSE 配置:
{
"mcpServers": {
"stylist-remote": {
"command": "npx",
"args": [
"-y", "mcp-remote",
"https://stylist.polly.wang/sse?apiKey=YOUR_API_KEY",
"--transport", "sse-only"
]
}
}
}
显然 Streamable HTTP 更加优雅。
SSE 模式(兼容旧客户端)
对于跨机器访问(比如从我的MacBook连接到Azure VM上的服务),SSE是必须的。
Starlette异步服务器
from starlette.applications import Starlette
from starlette.routing import Route, Mount
from mcp.server.sse import SseServerTransport
app = Starlette(
routes=[
Route("/health", health_check),
Route("/sse", sse_handler),
Route("/messages/", message_handler, methods=["POST"]),
Mount("/images", StaticFiles(directory=DRESSCODE_ROOT)),
],
middleware=[Middleware(APIKeyMiddleware)]
)
API Key认证
为了安全性,我实现了API Key认证中间件:
class APIKeyMiddleware:
PUBLIC_PATHS = {"/health", "/favicon.ico"}
PUBLIC_PREFIXES = ("/images/",) # 图片不需要认证
async def __call__(self, scope, receive, send):
if self._is_public_path(scope["path"]):
return await self.app(scope, receive, send)
api_key = self._extract_api_key(scope)
if api_key != self.expected_key:
response = Response("Unauthorized", status_code=401)
return await response(scope, receive, send)
await self.app(scope, receive, send)
支持三种认证方式:
- Query参数:
?apiKey=xxx - Header:
X-API-Key: xxx - Bearer Token:
Authorization: Bearer xxx
Nginx + Let's Encrypt
生产环境使用Nginx作为反向代理,Let's Encrypt提供免费SSL证书:
server {
listen 443 ssl;
server_name stylist.polly.wang;
ssl_certificate /etc/letsencrypt/live/stylist.polly.wang/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/stylist.polly.wang/privkey.pem;
location / {
proxy_pass http://127.0.0.1:8888;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_buffering off; # SSE必须禁用缓冲
proxy_read_timeout 86400; # 长连接超时
}
}
关键配置:
proxy_buffering off: SSE必须禁用响应缓冲proxy_read_timeout 86400: 保持长连接24小时
第五步:服装图片直接访问
MCP协议的一个限制是不支持直接传输二进制数据。最初我设计了一个get_garment_image工具返回base64编码的图片,但这既低效又不优雅。
更好的方案:直接在推荐结果中返回图片URL。
def _format_garment(self, garment, include_image_url=True):
result = {
"garment_id": garment["garment_id"],
"category": garment["category"],
"description": garment["description"],
# ...
}
if include_image_url:
# 生成HTTPS图片URL
result["image_url"] = f"https://{MCP_EXTERNAL_HOST}/images/{category}/images/{garment_id}_1.jpg"
return result
这样客户端可以直接在浏览器中打开图片链接,无需额外的API调用。
测试套件
为了确保系统稳定性,我编写了一个综合测试脚本(14个测试用例):
python scripts/test_mcp.py
测试覆盖:
- 📦 数据库测试: 基本搜索、过滤器、多类别
- 👕 单品模式: T恤、连衣裙、中文查询
- 👔 全套穿搭: 基础、正式场合、中文、男装(无连衣裙)
- 🧠 LLM推理: 评分、理由、搭配建议
- 🌐 远程服务: Health端点、Tools端点、图片访问
输出示例:
======================================================================
Test Summary
======================================================================
✅ GarmentDatabase Basic (53789 garments)
✅ GarmentDatabase Filters (All filters work)
✅ Single Item: T-shirt (5 results)
✅ Single Item: Dress (5 results, category=dresses)
✅ Full Outfit: Basic (3 outfits)
✅ Full Outfit with Reasoning (3 outfits, 8.7s)
...
==============================
14/14 tests passed
🎉 All tests passed!
第六步:Skill 开发——让展示更优雅
MCP Server 返回的是结构化 JSON 数据,虽然信息完整,但直接展示给用户并不友好。于是我开发了配套的 stylist-presenter Skill,将推荐结果转化为精美的可视化报告。
MCP + Skill 协作模式
用户请求 → Skill 触发 → 调用 MCP Tool → 解析结果 → 生成 HTML 报告 → 浏览器预览
Skill 的核心价值:
- 自动触发:识别「穿搭推荐」「约会穿什么」等关键词
- 格式转换:将 JSON 转为美观的 HTML 页面
- 文件输出:生成独立的报告文件,可保存分享
HTML 报告设计
我设计了一套黑金配色的视觉风格:
/* 核心配色 */
--header-bg: #1a1a1a; /* 黑色背景 */
--accent-color: #c9a86c; /* 金色强调 */
--card-bg: #ffffff; /* 白色卡片 */
--advice-bg: #fff3cd; /* 黄色建议区 */
报告包含:
- 推荐卡片:编号、标题、推荐度评分
- 标签系统:风格、场合、颜色等 hover 交互
- 图片网格:悬停放大效果
- 造型师建议:黄色高亮区块
- 后续推荐:引导用户继续探索
Skill 文件结构
stylist-presenter/
├── SKILL.md # 主指令文件
└── references/
└── html-template.html # 完整 HTML 模板
通过这种 MCP + Skill 的组合,用户只需说「推荐约会穿搭」,就能得到一份精美的可视化报告,而不是冷冰冰的 JSON。
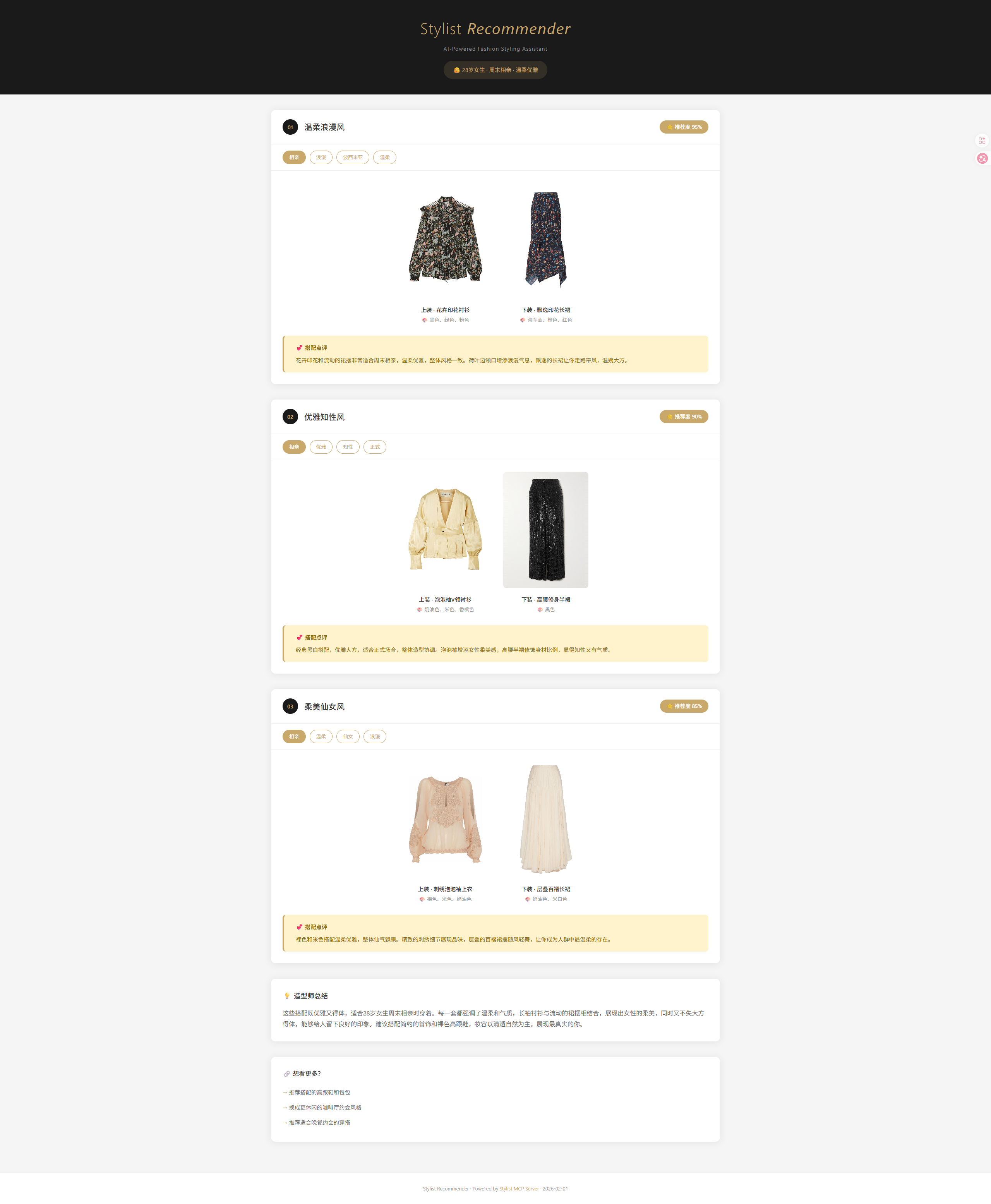
成果展示
最终的系统支持这样的交互:
用户查询:"推荐3套适合约会的优雅穿搭"
系统响应:
{
"mode": "full_outfit",
"num_outfits": 3,
"outfits": [
{
"type": "dress",
"dress": {
"garment_id": "033207",
"description": "Elegant midi dress with subtle texture",
"image_url": "https://stylist.polly.wang/images/dresses/images/033207_1.jpg"
},
"score": 9.2,
"reason": "经典的中长连衣裙,完美适合约会场合..."
}
],
"stylist_advice": "这些穿搭都非常适合约会场合。连衣裙展现优雅气质,而上衣+裙子的组合则更加灵活多变..."
}
总结与反思
技术收获
- MCP协议的实践:从stdio到SSE再到Streamable HTTP,深入理解了MCP的设计哲学和演进方向
- 跨模型兼容性:不同LLM对prompt的理解差异,需要针对性优化
- 向量检索+LLM推理:混合架构在时尚推荐场景的有效应用
- 生产级部署:Nginx反向代理、SSL证书、API认证的完整实践
- MCP + Skill 协作:数据层与展示层分离,MCP 负责能力,Skill 负责体验
未来改进方向
- 多模态输入:支持用户上传图片,实现"找相似"功能
- 用户画像:记住用户偏好,提供个性化推荐
- 实时库存:对接电商平台,显示可购买状态
- 更多 Skill:开发 PPT 生成、社交分享等配套 Skill
项目地址
GitHub: Polly2014/Stylist-MCP-Server
如果你对MCP Server开发或AI时尚应用感兴趣,欢迎Star和交流!
写作这篇博文的过程,也是对整个项目的一次复盘。从最初的想法到生产可用,涉及的技术点远比预想的要多。但正是这些细节的打磨,才让最终的产品既稳定又优雅。