
一、项目背景与意义
财务报告是了解企业经营状况的重要窗口,但获取和分析财报数据对普通投资者而言颇具挑战性。用户需要熟悉各大交易所网站结构、数据格式及财务分析方法,这无疑提高了入门门槛。为解决这一痛点,我们开发了基于FastAPI的财报数据爬取与分析平台,旨在用图形化界面封装复杂的数据获取和分析流程,使不具备专业背景的用户也能轻松获取和理解企业财务数据。
二、技术栈选择
在技术选型上,考虑了开发效率、性能和用户体验:
- Python - 作为主要开发语言,兼具开发效率和强大的数据处理能力
- FastAPI - 高性能的Web框架,提供异步支持和自动API文档
- Jinja2 - 灵活的模板引擎,用于前端页面渲染
- Bootstrap - 响应式前端框架,确保良好的跨设备体验
- Requests & BeautifulSoup - 强大的网络请求和HTML解析库
- PDFPlumber - PDF文档解析工具,用于提取财报文本
- LiteLLM - 大语言模型接口封装,用于智能财报分析
- Docker - 容器化部署,确保环境一致性
三、架构设计
应用采用分层架构,明确职责分离:
Financial Platform
├── 数据模型层 (Models)
├── 路由控制层 (Routers)
├── 服务逻辑层 (Services)
│ ├── 爬虫服务 (CrawlerService)
│ ├── 分析服务 (AnalysisService)
│ └── LLM分析服务 (LLMAnalysisService)
├── 模板视图层 (Templates)
└── 静态资源层 (Static)
每个模块职责单一,减少耦合性,提高代码可维护性。这种设计能够独立优化各个组件,例如改进爬虫算法而不影响分析逻辑。
四、关键功能实现
4.1 智能财报爬虫
def crawl_annual_report_from_cninfo(self, stock_code: str, year: int, report_type: str = "年度报告") -> Dict[str, Any]:
"""从巨潮资讯网爬取财务报告"""
logger.info(f"开始爬取 {stock_code} {year}年 {report_type}")
# 构建搜索关键词
search_key = f"{stock_code} {year}年{report_type}"
# 构造巨潮资讯网搜索URL和参数
base_url = "http://www.cninfo.com.cn/new/fulltextSearch/full"
params = {
"searchkey": search_key,
"sdate": "",
"edate": "",
"isfulltext": "false",
"sortName": "pubdate",
"sortType": "desc",
"pageNum": 1,
"pageSize": 10
}
try:
# 增加随机延迟,避免反爬
delay = random.uniform(2, 5)
logger.info(f"等待 {delay:.2f} 秒后发送请求")
time.sleep(delay)
# 发送请求
response = requests.post(base_url, headers=self.headers, data=params, timeout=30)
response.raise_for_status()
# 解析JSON响应
result = response.json()
# ... 处理响应数据 ...
爬虫服务是应用的核心功能之一,通过智能解析各大财经网站结构,自动获取财报PDF文件并提取文本内容,为后续分析提供数据基础。
4.2 财报数据分析
def extract_financial_indicators(self, report_content: str) -> Dict[str, Any]:
"""从财报内容中提取关键财务指标"""
indicators = {
"revenue": None,
"net_profit": None,
"total_assets": None,
"total_liabilities": None,
"equity": None,
"cash_flow_from_operations": None,
"eps": None,
"roe": None,
# ... 更多指标 ...
}
# 使用正则表达式提取数据
revenue_pattern = r"营业收入[^\d]+([\d,\.]+)"
revenue_match = re.search(revenue_pattern, report_content)
if revenue_match:
indicators["revenue"] = self._convert_to_number(revenue_match.group(1))
# ... 提取更多指标 ...
return indicators
分析服务负责从财报文本中提取关键财务指标,并计算重要财务比率,为用户提供直观的财务状况概览。
4.3 LLM智能分析
def analyze_financial_report(self, report_content: str, company_info: Dict[str, str]) -> Dict[str, Any]:
"""使用LLM分析财报内容"""
if not self.api_key:
logger.warning("未提供API密钥,使用模拟数据")
return self._get_mock_analysis_result(company_info)
# 构建提示词
prompt = self._build_analysis_prompt(report_content, company_info)
try:
# 使用litellm调用LLM API
response = litellm.completion(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
temperature=0.2,
max_tokens=2000
)
# 解析响应
return self._parse_llm_response(response)
except Exception as e:
logger.error(f"LLM API调用失败: {str(e)}")
return {
"status": "error",
"message": f"分析失败: {str(e)}"
}
LLM分析服务是平台的创新亮点,通过集成大语言模型,提供专业级的财报解读和投资建议,大幅降低了财报分析的专业门槛。
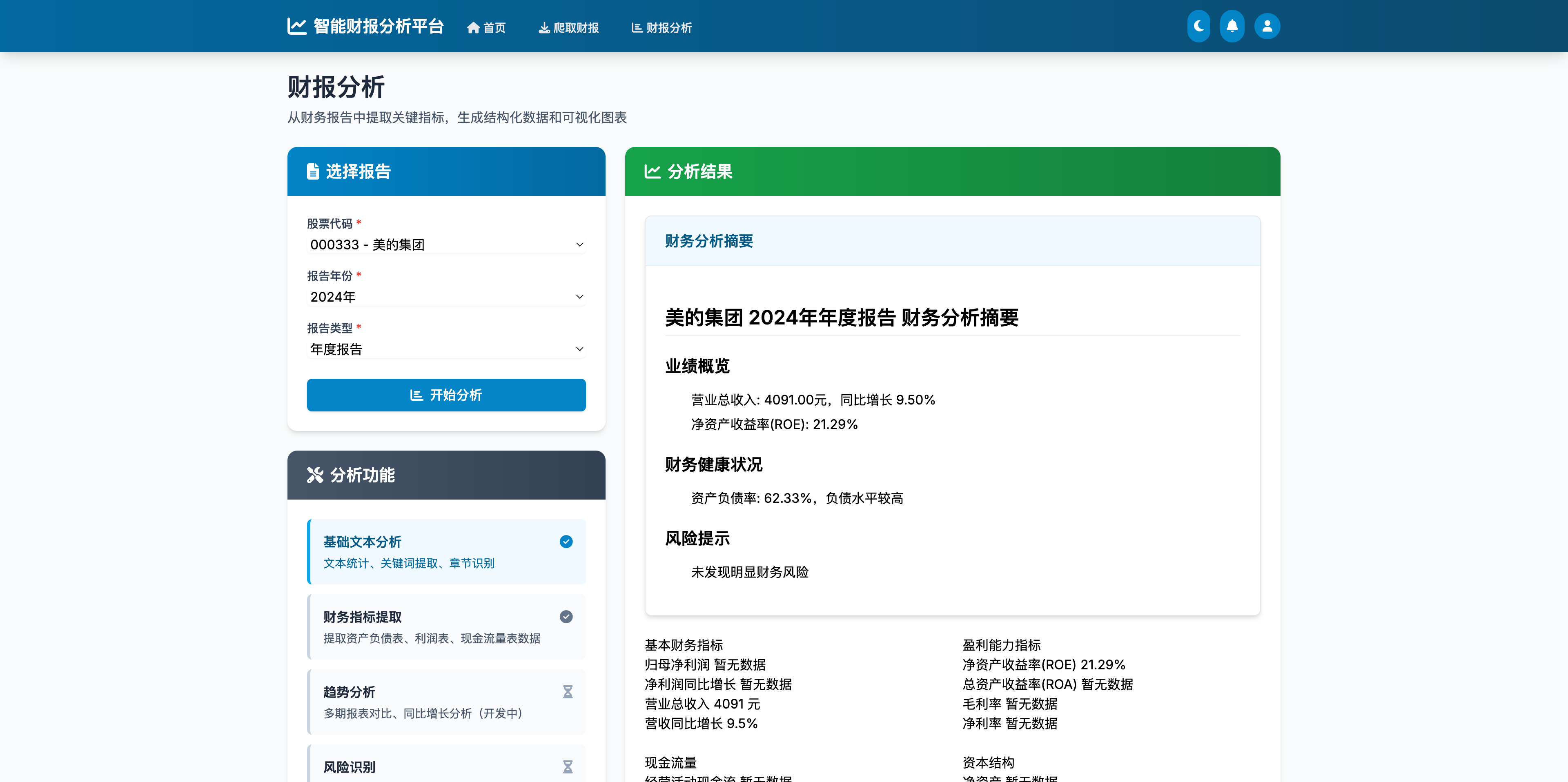
4.4 用户友好的Web界面
<div class="container mt-4">
<div class="row">
<div class="col-md-6">
<div class="card">
<div class="card-header bg-primary text-white">
<h5 class="card-title mb-0">财报获取</h5>
</div>
<div class="card-body">
<form id="crawlerForm">
<div class="mb-3">
<label for="stockCode" class="form-label">股票代码</label>
<input type="text" class="form-control" id="stockCode" name="stock_code" required>
</div>
<!-- ... 更多表单字段 ... -->
<button type="submit" class="btn btn-primary">获取财报</button>
</form>
</div>
</div>
</div>
<!-- ... 更多卡片 ... -->
</div>
</div>
Web界面采用直观的卡片式布局,将复杂的功能模块化展示,用户可以轻松完成从财报获取到智能分析的全流程操作。
五、解决的技术难题
5.1 反爬机制应对
在开发过程中,发现巨潮资讯网等网站有较为严格的反爬机制,直接请求容易被封禁IP。
解决方案:实现了智能请求策略,包括随机延时、User-Agent轮换和指数退避重试:
def _make_request_with_retry(self, url, method="GET", data=None, max_retries=3):
"""带重试机制的请求方法"""
headers_list = [
{"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"},
{"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"},
{"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36"}
]
for attempt in range(max_retries):
try:
# 随机延时
time.sleep(random.uniform(2, 5))
# 随机选择User-Agent
headers = random.choice(headers_list)
headers.update(self.base_headers)
if method.upper() == "GET":
response = requests.get(url, headers=headers, timeout=30)
else:
response = requests.post(url, headers=headers, data=data, timeout=30)
response.raise_for_status()
return response
except Exception as e:
logger.warning(f"请求失败 (尝试 {attempt+1}/{max_retries}): {str(e)}")
# 指数退避
time.sleep((2 ** attempt) + random.random())
raise Exception(f"请求失败,已达到最大重试次数: {max_retries}")
5.2 PDF文本提取优化
财报PDF格式复杂多样,直接提取文本常出现格式混乱、表格数据丢失等问题。
解决方案:开发了专用的PDF处理流程,结合页面布局分析和表格识别:
def extract_text_from_pdf(self, pdf_path: Path, save_text: bool = True) -> Optional[str]:
"""从PDF提取文本内容"""
try:
logger.info(f"开始从PDF提取文本: {pdf_path}")
text_content = []
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
# 提取表格
tables = page.extract_tables()
if tables:
for table in tables:
# 将表格转换为文本格式
table_text = self._format_table(table)
text_content.append(table_text)
# 提取正文文本
text = page.extract_text() or ""
text_content.append(text)
# 后处理:清理多余空白、合并段落等
full_text = self._post_process_text("\n\n".join(text_content))
if save_text:
text_path = pdf_path.with_suffix('.txt')
with open(text_path, 'w', encoding='utf-8') as f:
f.write(full_text)
logger.info(f"文本内容已保存至: {text_path}")
return full_text
except Exception as e:
logger.error(f"提取PDF文本时出错: {str(e)}")
return None
5.3 LLM响应解析
LLM返回的分析结果格式不统一,需要智能解析以提取结构化数据。
解决方案:实现了基于模式识别的响应解析器:
def _parse_llm_response(self, response) -> Dict[str, Any]:
"""解析LLM响应"""
try:
# 从litellm响应中提取内容
if hasattr(response, 'choices') and response.choices:
content = response.choices[0].message.content
else:
# 兼容不同的响应格式
content = response.get('choices', [{}])[0].get('message', {}).get('content', '')
# 尝试提取JSON部分
json_match = re.search(r'```json\s*([\s\S]*?)\s*```', content)
if json_match:
json_str = json_match.group(1)
try:
return json.loads(json_str)
except:
pass
# 如果没有JSON格式,尝试解析结构化文本
result = {
"status": "success",
"analysis": {},
"summary": "",
"recommendations": []
}
# 提取摘要部分
summary_match = re.search(r'摘要[::]([\s\S]*?)(?=\n\n|$)', content)
if summary_match:
result["summary"] = summary_match.group(1).strip()
# ... 提取更多结构化内容 ...
return result
except Exception as e:
logger.error(f"解析LLM响应时出错: {str(e)}")
return {
"status": "error",
"message": f"解析响应失败: {str(e)}"
}
六、部署与运行
应用支持多种部署方式,包括Docker容器化部署和传统服务器部署:
#!/bin/bash
# run.sh - 应用启动脚本
# 设置环境变量
export PORT=12001
export OPENAI_API_KEY="your-api-key-here"
# 安装依赖
pip install -r requirements.txt
# 启动应用
uvicorn main:app --host 0.0.0.0 --port $PORT --reload
Docker部署更加简便,只需一行命令即可启动完整环境:
docker build -t financial-platform . && docker run -p 12001:12001 -e OPENAI_API_KEY="your-api-key" financial-platform
七、项目总结与展望
基于FastAPI的财报数据爬取与分析平台的开发是一次将复杂金融数据处理流程简化为用户友好界面的尝试。通过精心的架构设计和UI优化,成功降低了财报获取和分析的门槛,实现了预期目标。
在未来版本中,计划进一步优化:
- 扩展数据源,支持更多交易所和财经网站
- 增强数据可视化能力,提供交互式图表
- 实现财报数据的历史对比和行业对标分析
- 优化LLM分析能力,提供更专业的投资建议
- 添加用户账户系统,支持个性化设置和收藏
源码地址:GitHub - Financial Platform
八、开发过程中的对话记录
以下是与AI助手的部分关键对话,展示了项目的构思和实现过程:
初始需求描述
用户:你是一个专业的财报数据爬虫助手,专注于从各种公开渠道获取企业财务报告原始文件。帮我构建一个基于fastapi的Web站点,实现上述功能(用户输入或选择公司名称、股票代码等信息)后台调用爬虫获取数据,前端可以展示和下载。同时首页预留出"财报分析"的功能
爬虫服务实现
AI助手:我将为您构建一个基于FastAPI的财报数据爬虫Web应用。首先,让我们设计项目结构:
financial_crawler/ ├── app/ │ ├── models/ │ ├── routers/ │ └── services/ ├── static/ ├── templates/ ├── main.py └── requirements.txt接下来,我们需要实现爬虫服务,它将负责从巨潮资讯网等渠道获取财报数据...
LLM分析功能集成
用户:现在我想增加一个基于LLM的财报智能分析功能,可以自动解读财报并给出投资建议
AI助手:这是一个很好的想法!我们可以集成OpenAI的GPT或其他LLM模型来实现财报智能分析。我将创建一个新的LLMAnalysisService类和相应的路由...
class LLMAnalysisService: """LLM财报分析服务""" def __init__(self, api_key: str = "", model_name: str = "gpt-3.5-turbo"): self.api_key = api_key self.model_name = model_name def analyze_financial_report(self, report_content: str, company_info: Dict[str, str]) -> Dict[str, Any]: """使用LLM分析财报内容""" # 实现代码...
部署与优化
用户:我们需要确保应用在生产环境中稳定运行,有什么建议?
AI助手:为了确保应用在生产环境中稳定运行,我建议以下几点:
- 使用Docker容器化部署,确保环境一致性
- 实现健壮的错误处理和日志记录
- 添加请求限流和缓存机制
- 使用环境变量管理敏感配置
- 实现定时任务,自动更新财报数据
我将为您创建Dockerfile和部署脚本...
九、结语
财报数据爬取与分析平台的开发过程展示了如何将复杂的金融数据处理流程转化为易用的Web应用。通过合理的架构设计、先进的技术选型和用户体验优化,我们成功构建了一个功能完备的财报分析工具,为投资者提供了便捷的数据获取和智能分析服务。
希望本文的开发经验能为类似项目提供有价值的参考,也欢迎社区贡献代码,共同完善这一平台。